OpenInsight 10.2 adds a new event called CELLPOSCHANGED to the EDITTABLE control. This is effectively the same as the normal POSCHANGED event but with the addition of an extra parameter called “ContextFlags” that provides more information on why the event was raised.
ContextFlags is a simple bitmask integer that contains the following flags:
Bit Flag Value
Description
0x00000001
If set then the cell position was changed via a keystroke.
0x00000002
If set then the cell position was changed via the mouse.
Equates for these flags can be found in the PS_EDITTABLE_EQUATES insert record:
Equ PS_EDT_CTF_NONE$ To 0x00000000;
Equ PS_EDT_CTF_KEYSTROKE$ To 0x00000001;
Equ PS_EDT_CTF_MOUSECLICK$ To 0x00000002;
Example – testing to see if the position (CARETPOS) was changed via a mouse click:
$Insert PS_EditTable_Equates
If BitAnd( ContextFlags, PS_EDT_CTF_MOUSECLICK$ ) Then
// CARETPOS was changed by using the mouse.
...
End
Notes on using the CELLPOSCHANGED event
The default promoted system CELLPOSCHANGED event handler performs the same processing as the default promoted system POSCHANGED event handler (i.e. data validation and required checking etc).
If a CELLPOSCHANGED event handler is defined by the developer then a standard POSCHANGED event will not be raised.
To preserve backwards compatibility with existing applications the default promoted system CELLPOSCHANGED event will not be compiled into a control if there is no CELLPOSCHANGED quick event handler. This is to ensure that POSCHANGED is always executed if CELLPOSCHANGED has not been explicitly set for a control by the developer.
CELLPOSCHANGED is available in OpenInsight 10.2 from the Beta 3 release onwards.
Based on user feedback (and our own experience) version 10.2 includes the following new updates for the OpenInsight migration process that we think you’ll find invaluable when moving your applications:
The ability to choose individual migration tasks
The ability to select individual entities
The ability to migrate SYSPROG components
We’ll take a look at each of these features below, along with a small note on “migrating” your data.
Task Selection
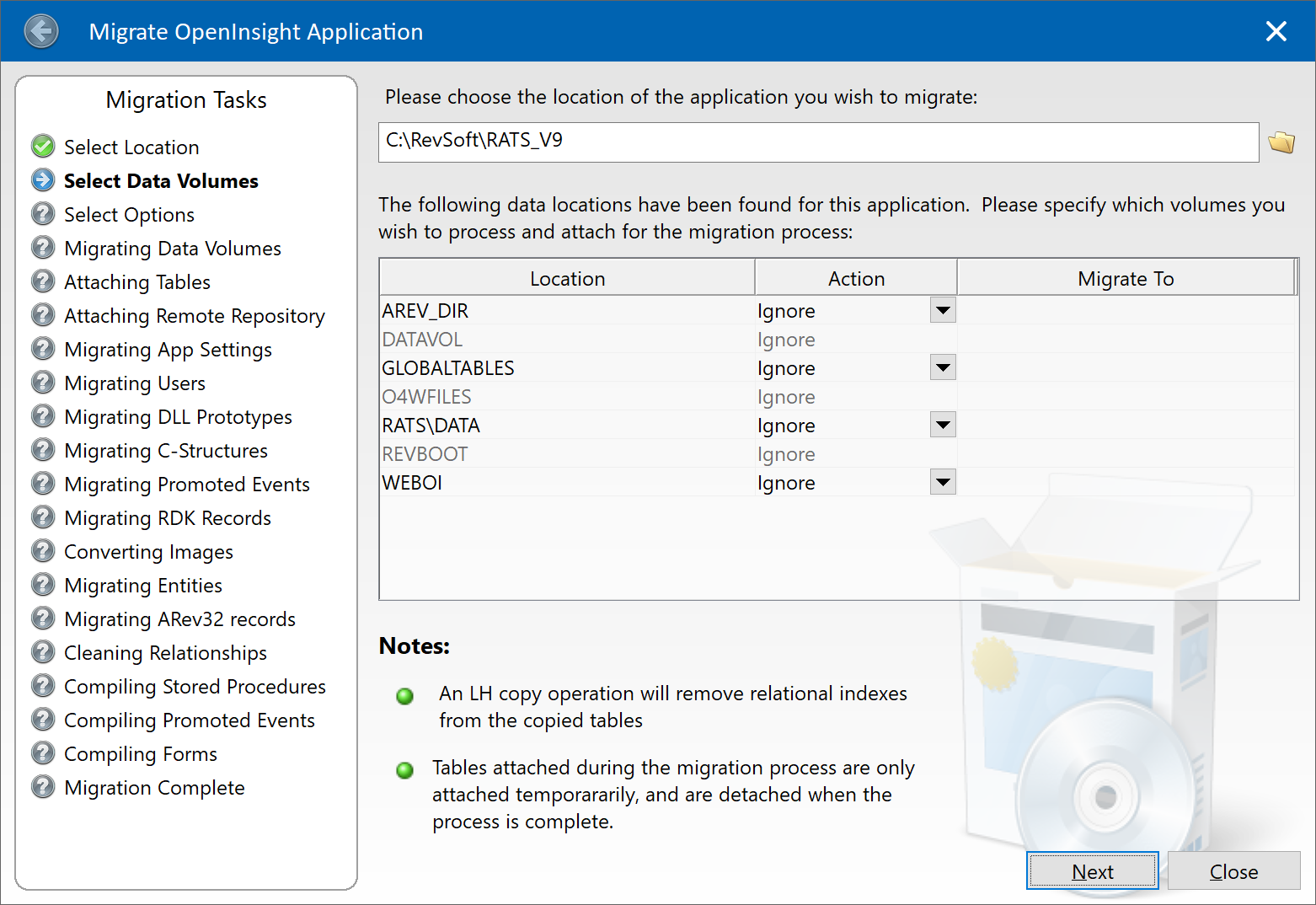
In previous releases the Migration Tool had a fixed set of tasks to perform which it did in sequence. In this release you may now specify which tasks you wish to execute instead, which might save some time if you have to repeat the migration process more than once (a common requirement if needing to keep a version 9 application synchronized with version 10 during upgrade development).
Migration Tool Selection Page
By default all tasks are selected, but you may deselect any that you don’t wish to run.
Task
Description
Migrate App Settings
Migrates information from the SYSAPPS record. Migrates database environment settings. Migrates custom event (CFG_EVENTS) settings.
Migrate Users
Migrates user details into the SYSUSERS table.
Migrate DLL Prototypes
Migrates “DLL_” records in SYSPROCS to DLLPROTOTYPE entities.
Migrate C-Structures
Migrates “STRUCT_” records in SYSOBJ to DLLSTRUCT entities.
Migrate Promoted Events
Migrates promoted event records in SYSREPOSEVENTS/EXES to PROMOTEDEVENT/EXE entities.
Migrate RDK records
Migrates SYSREPOSVIEWS/RELEASES records to REPVIEW/RELEASE entities.
Migrate Entities
Migrates application entities. Note that these can now be specified individually if desired (see below).
Migrate Arev32 records
Migrates Arev32-specific records in SYSENV. Migrates Arev32 records from SYSPRINTERS.
Clean Relationships
Removes invalid relationships (Using/Used By).
Compile Stored Procedures
Compiles migrated stored procedures.
Compile Promoted Events
Compiles migrated promoted events.
Compile Forms
Compiles migrated forms.
Migration Tool Tasks
Entity Selection
If you choose the “Migrate Entities” task then you now have the option to select individual entities to migrate (If you don’t select any then all entities in the v9 application will be migrated).
To select individual entities right-click on the “Selected Entities” control and choose “Select Entities” from the menu, or click the “…” options button in the top-right of the control’s header:
Selected Entities option button
You may now use the “Select Repository Entities” dialog to choose which entities you wish to migrate:
Select Repository Entities dialog
As you can see there are quite a few options you can use to find the entities you wish to migrate – these options make a “repository filter” that is used to create a list to choose from:
Option
Description
Filter ID
Name of a saved filter (REPFILTER entity). Choosing a filter will load the other selection criteria controls in this dialog with the saved filter details.
View ID
Name of a saved Repository View (REPVIEW entity). If specified, the list of entities in this View is used as a starting point for the filter when it executes.
Entity ID
If specified only entities matching this name will be selected. The standard ‘[]’,’]’ and ‘[‘ RList-style syntax for “containing”, “starting with” and “ending with” is respected.
Date From
If specified only entities updated from this date will be included. This option supports a “nD” syntax where “n” is the number of days since the current date. E.g. to select entities updated since the previous day specify “1D”, for entities updated in the last week specify “7D” and so on.
Date To
If specified do not include entities after this date. This option supports the same “nD” syntax as the “Date From” option.
Updated By
If specified then only entities updated by the specified user(s) are returned. This option may contain a “,” delimited list for matching against multiple users.
Filter Options
Only entities matching the checked options will be returned. Note that for a migration operation the “Show Inherited Entities” checkbox is always disabled (This dialog is used elsewhere in the system to select repository entities, so it can be enabled in such scenarios).
Filter By Types
Allows you to choose specific entity types and classes to include. If blank then all types and classes are included in the search. Click the “…” options button in the top right corner of the control, or right-click to use the context menu to launch a dialog to select the types and classes.
Filter By SELECT
This option allows you to enter an RLIST SELECT statement against the SYSREPOS table that will be used to filter the entities.
Save Filter
Click this button to save the filter criteria for future re-use (stored as a REPFILTER entity in the repository).
Apply Filter
Click this button to execute the filter criteria and load a list of matching entities into the “Available” controls below. If you have not entered any criteria then all entities in the v9 application will be selected.
Filter Options
Once you have applied your filter the “Available Types” control is populated – selecting a Type populates the “Available Entities” control where you can select the items that you wish to migrate. Use the “>” and “>>” buttons to add them to the “Selected Entities” control on the right, or the “<” and “<<” buttons to remove them.
Selecting Entities in the dialog
Things to note:
As items in the “Available Entities” control are selected, the list of items that they use is shown in the “Related (Used By) Entities” control below. These can also be selected if you wish.
Each of the “Available” and “Selected” controls have context menus and “…” options buttons (top-right corner).
If the “Auto-Add Executable” option is checked when you add entities to the “Selected Entities” control then any executable versions of the entity (e.g. STPROCEXE, OIWINEXE etc) are also added.
If the “Auto-Add Source” option is checked when you add entities to the “Selected Entities” control then any source versions of an executable entity (e.g. STPROC, OIWIN etc) are also added.
Clicking “OK” takes you back to the main migration form where you will see the list of entities selected. From there you may click the “Next” button to start the migration process.
(Note that the task and entity selections are saved automatically between migrations so that you may use them again if you wish.)
Migrating items from SYSPROG
Previous versions of the migration tool prevented migrating any entities from the SYSPROG application. This was to preserve the system from being damaged in case older v9 entities overwrote the v10 ones, thereby rendering it unusable.
With this release you may run the migration form from your SYSPROG application with the following restrictions:
You may only execute the following tasks:
Migrate RDK Records
Migrate Entities – You must specify the entities to migrate – you cannot migrate “All Entities”!
Migrate Arev32 Records
Clean Relationships
Compile Stored Procedures
Compile Forms
Migrating SYSPROG options
Bonus Trivia – a quick note on migrating data
The migration process begins with creating a new application in version 10 and then executing a form called RTI_MIGRATE_V9_TO_V10, which guides you through the steps necessary to move your application from version 9.
Migration Tool Start Page
At this point you select the location of the application you are migrating from, after which you see the data volumes that are attached in it. There are options for the data to be “migrated”, but in my experience it is best to move and attach the data you want for your application before you attempt the migration rather than use the facility here. The migration process does not change your data at all so there is no real advantage to using this facility (it is basically provided as a convenience), and in fact, if you are moving tables containing relational indexes they will be removed. It is far easier to copy/move and attach the tables yourself using the Database ToolPanel before you get here.
More Bonus Trivia – Sharing index data between v9 and v10
While on the topic of migrating data it is also worth taking a look at the end of this blog post by Sprezzatura if you intend to share your tables between v9 and v10 systems – you must make sure that you run the indexing system in a v9 compatible format:
The migration tool has been significantly improved for the version 10.2 release and we’re sure you will find it much more helpful when moving your older applications to the latest version of OpenInsight.
One of the new features that was added to the ListBox and TreeListBox controls in version 10 was the ability to use “in-place” editing on the items in the same manner as the Windows Explorer when you press “F2” or double-click an item. If you’ve done any work with the OpenInsight Menu Designers you will have seen this capability in action.
In-place editing for an item
The READONLY property
Enabling in-place editing is as simple as setting the READONLY property to False – once you’ve done that the user can press “F2” while using the control and edit the text of the currently selected item. Pressing “Enter” when editing will update the item text (as will losing focus or selecting another item), while pressing “Esc” will abandon the changes. Obviously that’s a very simple take on the topic and hardly worth a blog post in and of itself, so next we’ll take a look at some of the properties, methods and events that you can use to tailor the editing process.
The EDITING property
This is a simple boolean property that returns TRUE$ if an item is being edited.
The EDITORHANDLE property
This property returns the HANDLE of the editor control if an item is being edited.
The EDITKEY property
By default, hitting “F2” on an item puts the control into “edit mode”, just like the Windows Explorer. However, if you wish to change this then you may use the EDITKEY property to select another key instead. The edit key is a Windows virtual key code and constants for these codes can be found in the MSWIN_VIRTUALKEY_EQUATES insert record.
The EDITOPTIONS property
This property allows you to fine-tune some of the validation options for the editor:
TextCase – Specifies if the text entered is lower-case only, upper-case only or mixed (See the EDITLINE TEXTCASE property for more details).
ValidChars – Specifies which characters may be entered into the editor (See the EDITLINE VALIDCHARS property for more details).
MaxLimit – Specifies the maximum number of characters that may be entered into the editor (See the EDITLINE LIMIT property for more details).
At runtime this property is an @fm-delimited array – constants for use with this property can be found in the PS_LISTBOX_EQUATES insert record.
The INCLUDEEDITORTEXT property
By default getting item text from the ListBox (e.g. via the LIST property) will include the text from an item currently being edited, even if that edited text has not yet been saved. Setting this property to FALSE$ ensures that the returned item text ignores the value in the editor instead.
The BEGINEDIT method
This method allows you to programmatically put the ListBox into edit mode, as if the user had pressed “F2” (or whatever value the EDITKEY property is set to). You may specify the index of the item to edit, otherwise it will default to the current item.
This method allows you to programmatically stop the item editing process, optionally allowing any changes to be accepted as if the “Enter” key had been pressed (the default is to reject any changes as if the “Esc” key had been pressed).
This event is raised when the item is updated via the editor, i.e. the user hit the “Enter” key, the control lost the focus, or the EDITEDIT method was used with the bUpdate parameter set to TRUE$. The event passes the index of the item that has changed as well as the old and new data:
This event is raised when an item leaves edit mode without being updated, i.e. the user hit the “Esc” key or the EDITEDIT method was used with the bUpdate parameter set to FALSE$. The event passes the index of the item that was being edited:
So that wraps up this short post on ListBox editing – we’re sure that you’ll find many useful ways of implementing this new feature when expanding your application’s functionality.
As you can see, setting up the control is fairly easy, but the bulk of the work needs to be done in the HTTPREQUEST event where you examine the contents of the request and return the appropriate content.
Type of control firing the event – this is always “HTTPSERVER”
RequestID
Unique identifier for returning a response to the client – this is used with the various “SETRESPONSE” methods that set response data.
RequestHeaders
An @FM delimited dynamic array of data that describes the request. The format is similar to the HTTPRequest argument used in OECGI programming. The full format is described in the PS_HTTPSERVER_EQUATES insert record.
As mentioned above, the RequestHeaders parameter describes the details of the request using a format similar to the format used in OECGI programming. There are some differences that are worth highlighting however:
For a GET request the query values are already parsed into their own fields (<37> and <38>) as an associated multi-value pair. They are not found unparsed in field <1> as per OECGI.
For a POST or PUT request the content is obtained using the GETREQUESTCONTENT method (see below) – it is not passed in the RequestHeaders variable.
Cookies are already parsed into their own fields (<39> and <40>) as an associated multi-value pair.
Headers are already parsed into their own fields (<35> and <36>) as an associated multi-value pair.
Note that out of the box we do not enforce any restrictions or framework on how you handle the request – compare this to classic OECGI programming where the “PathInfo” field is used to determine which “INET_” procedure is executed to fulfill it (via the RUN_INET_REQUEST stored procedure) There is no such requirement with the HTTPSERVER control, and you may create your own framework if you wish (although see the note on RTI_RUN_HTTPSERVER_REQUEST below).
Returning a response
There are several methods described below that you may use to process the content that you return to the client.
GETREQUESTCONTENT
GETRESPONSECONTENT
GETRESPONSECOOKIE
GETRESPONSEFILE
GETRESPONSEHEADER
GETRESPONSESTATUS
ISPORTINUSE
SETRESPONSECONTENT
SETRESPONSECOOKIE
SETRESPONSEFILE
SETRESPONSEHEADER
SETRESPONSESTATUS
SENDRESPONSE
Note: With each of these you must use the unique RequestID parameter passed to you in the HTTPREQUEST event.
IPv6 – if TRUE$ then check the IPv6 bindings, otherwise check the IPv4 bindings
SENDRESPONSE method
Sends the response back to the client. This method should be called when you have finished setting the response details (Note that this is called by the promoted system HTTPREQUEST handler in case you forgot to do it in your own code!).
CookieValue is an @fm-delimited array formatted as follows:
<1> Value
<2> Path
<3> Domain
<4> Expires (internal date format)
<5> Max Age (seconds)
<6> Secure (TRUE$/FALSE$)
<7> HttpOnly (TRUE$/FALSE$)
<8> SameSite
SETRESPONSEFILE method
If you have a file that contains the content you wish to return then you should use this method to let the server read the file and return it to the client itself. This offers better performance than reading the contents via Basic+ and using the SETRESPONSECONTENT method as it avoids any unnecessary copying of data.
As part of version 10.2 we have included a sample HTTPREQUEST event handler called RTI_RUN_HTTPSERVER_REQUEST which you can examine and copy for your own applications if you wish. It emulates the core behavior of the OECGI RUN_INET_REQUEST handler in that it uses the “PathInfo” field to determine the stored procedure to fulfill the request. In this case it looks for a matching procedure that has the prefix “HTTPSVR_” and we have included a couple of example “HTTPSVR_” procedures for you to review as well.
Conclusion
With the addition of the HTTPSERVER control it is now possible to provide HTML content directly from your application, and also provide a means of web-development directly from your desktop without necessarily needing to install a dedicated web-server like IIS.
It is also a good solution for when you want to provide local HTML content in your application’s user-interface via an embedded browser control, because it can avoid the usual security restrictions that browsers enforce for such scenarios.
Basic+ is a dynamically-typed language, and sometimes the system will attempt to change the type of a variable before using it in an operation. For example, if we have variable containing a numeric value as a string, and we attempt to compare it to a variable containing an actual numeric value, then the former will be coerced to a numeric format before the comparison, e.g.:
StrVar = "3" ; // String representing an integer
NumVar = 7 ; // Integer
Ans = ( StrVar = NumVar ) ; // Ans is FALSE$ and StrVar
; // is converted to an Integer
This works well in the vast majority of cases, but causes issues when attempting to compare strings that that could be numbers but really aren’t for the purposes of the comparison. For example, consider the following:
Var1 = "12" ; // String
Var2 = "012" ; // String
Ans = ( VarA = VarB ) ; // Ans = TRUE$ - should be FALSE$!!
The system first attempts to coerce the operands to a numeric format, and of course it can because they both evaluate to the number 12, and are therefore treated as equal. If you wish to compare them both as strings, the usual solution has been to change them so that they cannot be converted to a number, usually by prefixing them with a letter or symbol like so:
Var1 = "12" ; // String
Var2 = "012" ; // String
Ans = ( ( "X" : VarA ) = ( "X" : VarB ) ) ; // Ans = FALSE$
Although this works it hurts performance and can be a cumbersome solution.
OpenInsight 10.2 introduces a new set of extended comparison operators to Basic+ that ensure both operands are coerced to a string type (if needed) before being evaluated, and provides the following benefits:
Removes the need for any concatenation thereby avoiding unnecessary copying
Removes the need to check if a variable can be a number before the comparison
Makes it obvious that you are performing a “string-only” comparison so your code looks cleaner.
The new (case-sensitive) operators are:
Operator
Description
_eqs
Equals operator
_nes
Not Equals operator
_lts
Less Than operator
_les
Less Than Or Equals operator
_gts
Greater Than operator
_ges
Greater Than Or Equals operator
There is also matching set of case-insensitive operators too:
Operator
Description
_eqsc
Case-Insensitive Equals operator
_nesc
Case-Insensitive Not Equals operator
_ltsc
Case-Insensitive Less Than operator
_lesc
Case-Insensitive Less Than Or Equals operator
_gtsc
Case-Insensitive Greater Than operator
_gesc
Case-Insensitive Greater Than Or Equals operator
So we could write the previous example like so:
Var1 = "12" ; // String
Var2 = "012" ; // String
Ans = ( VarA _eqs VarB ) ; // Ans = FALSE$
Hopefully you’ll find this a useful addition when performing string-only comparisons in your own applications.
In previous versions of OpenInsight the usual way of accessing data from a multi-row select EditTable control was to get the SELPOS property and then iterate over the data pulling out the rows, e.g. something like this (not optimized, but you get the idea):
SelPos = Get_Property( CtrlEntID, "SELPOS" )
DataList = Get_Property( CtrlEntID, "LIST" )
SelList = ""
SelRows = SelPos<2>
SelCount = FieldCount( SelRows, @Vm )
For SelIdx = 1 To SelCount
SelRow = SelRows<0,SelIdx>
SelList<-1> = DataList<SelRow>
Next
However, in OpenInsight 10 we added a couple of new properties that allow you to access data in a multi-row select EditTable in a faster and more efficient way. These are:
The SELLIST property
The SELARRAY property
Both of these return data in the familiar LIST and ARRAY formats, but they only return data from the selected rows, thereby saving you the step of accessing SELPOS and iterating over the data yourself. So, to rewrite the example above we can now do this:
SelList = Get_Property( CtrlEntID, "SELLIST" )
Likewise, to return the data in ARRAY format we would use the SELARRAY property like so:
SelArray = Get_Property( CtrlEntID, "SELARRAY" )
Ergo, when asked the other day “What’s the fastest way of getting data from a specific column from the selected rows”, the answer was:
With the release of version 10.1 a new control type called DIRWATCHER (“Directory Watcher”) has been added to OpenInsight. This is a fairly simple control which allows you to monitor one or more directories on your system and then receive notifications when the contents are changed.
Using the control is very straightforward:
Use the WATCHDIR method to add a directory to monitor for changes.
Handle the CHANGED event to receive notifications of directory changes.
Use the STOP method to stop monitoring directories.
We’ll take a quick look at each of these methods and events below along with a couple of important properties:
The WATCHDIR method
This method allows you to specify a directory to monitor along with some optional flags. It may be called multiple times to watch more than one directory.
The flag values are specified in the MSWIN_FILENOTIFY_EQUATES insert record,
This method returns TRUE$ if successful, or FALSE$ otherwise.
The STOP method
This method stops the control monitoring its specified directories.
bSuccess = Exec_Method( CtrlEntID, "STOP" )
This method returns TRUE$ if successful, or FALSE$ otherwise.
(Note – to resume directory monitoring after the STOP method has been called the WATCHDIR method(s) must be executed again).
The CHANGED event
This event is raised when changes have been detected in the monitored directories.
bForward = CHANGED( NewData )
This event passes a single parameter called NewData which contains an @vm-delimited list of changed items (i.e. notifications). Each item in the list comprises an “action code” and the name and path of the affected file, delimited by an @svm.
Action codes are defined in the MSWIN_FILENOTIFY_EQUATES insert record like so:
equ FILE_ACTION_ADDED$ to 0x00000001
equ FILE_ACTION_REMOVED$ to 0x00000002
equ FILE_ACTION_MODIFIED$ to 0x00000003
equ FILE_ACTION_RENAMED_OLD_NAME$ to 0x00000004
equ FILE_ACTION_RENAMED_NEW_NAME$ to 0x00000005
Remarks
If a monitored directory experiences a high volume of changes (such as copying or removing thousands of files) it could generate a correspondingly high number of CHANGED events, which in turn could produce an adverse affect on your application and slow it down. In order to deal with this potential issue it is possible to “bundle up” multiple notifications with the NOTIFYTHRESHOLD property into a single CHANGED event so they may be processed more efficiently.
The NOTIFYTHRESHOLD property
The NOTIFYTHRESHOLD property is an integer that specifies the maximum number of notifications that should be bundled before a CHANGED event is raised.
The NOTIFYTIMER property is an integer that specifies the number of milliseconds before a CHANGED event is raised if the NOTIFYTHRESHOLD property value is not met.
If the NOTIFYTHRESHOLD property is set to a value greater than 1 then the control will try to bundle that number of notifications together before raising a CHANGED event. However, when this is set to a high value it is possible that the threshold may not be reached in a timely fashion and the CHANGED event not actually raised.
E.g. If the NOTIFYTHRESHOLD is set to 1000, and only 200 notifications are received then the CHANGED event would not be raised.
To prevent this problem the NOTIFYTIMER property may be used to specify the amount of time after receiving the last notification before a CHANGED event is raised even if the NOTIFYTHRESHOLD is not met.
E.g. in the example above, if the control had a NOTIFYTIMER of 50, then a CHANGED event would be raised 50ms after the last notification (200) was received, even though the NOTIFYTHRESHOLD of 1000 has not actually been met.
Developer Notes
The DIRWATCHER control is intended as a “non-visual” control and should probably be hidden at runtime in your own applications. However, it is actually derived from a normal STATIC control so all of the properties and methods that apply to a STATIC apply to the DIRWATCHER as well, and you may use them as normal if you wish.
When executing a long running process in a desktop environment, such as selecting records from a large table, it is important for the user to be able to interact with the application even though it is busy. A common example of this is displaying a dialog box that shows the progress of an operation and allowing the user to cancel it if they wish. Failure to provide this ability generally results in user frustration, or causes the dreaded “Window Ghosting” effect where Windows changes a form’s caption to “Not Responding” (this is never a good look, and usually ends in a quick visit to the Task Manager to kill the application).
In order to avoid this problem we have to allow the application to check for user interaction, a process usually referred to as “yielding” (hence the awful title of this post), and this time we’ll take a look at the various options available to accomplish this and the differences between them. Before we go any further however, here’s a little background information on how OpenInsight runs beneath the hood so that you can appreciate how messages and events are handled.
Under the hood
OpenInsight.exe (aka. the “Presentation Server”, or “PS”) has a main thread (the “UI thread”) with a Windows message loop that manages all of the forms and controls, and it also has an internal “event queue” for storing Basic+ events that need to be executed. The PS also creates an instance of the RevEngine virtual machine (“the engine”), which has its own thread (the “engine thread”) with a Windows message loop, and is responsible for executing Basic+ code.
When the PS needs to execute an event it passes it to the engine directly if possible, otherwise it adds the details to the event queue and then posts a message to itself so the queue can be checked and processed when the engine is not busy. When the engine receives the event data it is executed on the engine thread. Stored procedures such as Get_Property, Set_Property, and Exec_Method provide a way for the Basic+ event to communicate back to the PS to interact with the user interface controls and forms during its execution.
The key point to note here is that Basic+ event code runs in a different thread to the UI, so while the engine thread is processing the event, the UI thread is basically waiting for it to finish, and this means that it may or may not get chance to process it’s own message loop. This is where the problems can begin, and why the need for a yielding ability, because:
The engine thread needs to be paused or interrupted in some fashion so that the UI thread can check and process its own Windows message queue for things like mouse, keyboard and paint messages. If this queue is not checked at least every 10 seconds then Windows assumes that the PS is hung and the “Not Responding” captions are shown on the application forms.
While the engine is processing an event, the PS cannot pass it a new one, so it is added to the event queue. If we are waiting to process some Basic+ event code like a button CLICK to cancel the current operation, then we need some way for this to be retrieved and executed before the current event is finished.
So, now we know why “window ghosting” happens we can take a look at the various options to deal with it.
Options for yielding
MSWin_Sleep stored procedure
This is a direct call to the Windows API Sleep function, and it puts the engine thread to sleep for at least the specified number of milliseconds. However, while calling this will allow Windows to schedule another thread to run, there’s no guarantee that this would be the UI thread, so it’s not really a good solution.
WinYield stored procedure
This is a simple wrapper around the Windows API Sleep function, with a sleep-time of 10ms. This suffers from the same disadvantages discussed for MSWin_Sleep above (This function remains for backwards compatibility with early versions of of OI and Windows).
MSWin_SwitchToThread stored procedure
This is a direct call to the Windows API SwitchToThread function which forces Windows to schedule another thread for execution. Like MSWin_Sleep and WinYield there’s no guarantee that this would cause the UI thread to run, so again it’s not a great solution.
SYSTEM PROCESSEVENTS method (a.k.a Yield stored procedure)
This is a new method in version 10.1 that performs two tasks that solve the problem:
It explicitly tells the UI thread to process its message queue (which will avoid the “ghosting” issue), and
It allows the UI thread to process the event queue so waiting events can be executed as well.
One possible drawback here is that waiting events are also processed, and this might not be a desirable outcome depending on what you are doing. In this case there is another method called PROCESSWINMGS that should be used instead.
(FYI – The PROCESSEVENTS method is essentially a wrapper around the venerable Yield() stored procedure, but allows the same functionality to be called via the standard object-based method API rather than as a “flat” function. Yield() itself is still and will be fully supported in the product).
SYSTEM PROCESSWINMSGS method
This is a new method in version 10.1 that tells the PS to process it’s Windows message queue but it does not process any Basic+ events, i.e. it prevents the “ghosting” effect but does not cause events to fire before your application is ready for them.
Conclusion
Version 10.1 has added more functionality to help you avoid the dreaded “Not Responding” message via the PROCESSWINMGS and PROCESSEVENTS methods, and hopefully, armed with the information above, this will help you to write better integrated desktop-applications.
In the current OpenInsight 10.1 Beta program, Martyn at RevSoft UK had reported a bug about the Height property creeping up by a pixel each time he opened a form. This was traced to the point when the menu structure was parsed and created: it was actually inserting an extra pixel, so this was fixed and the form Height now stayed the same between each opening.
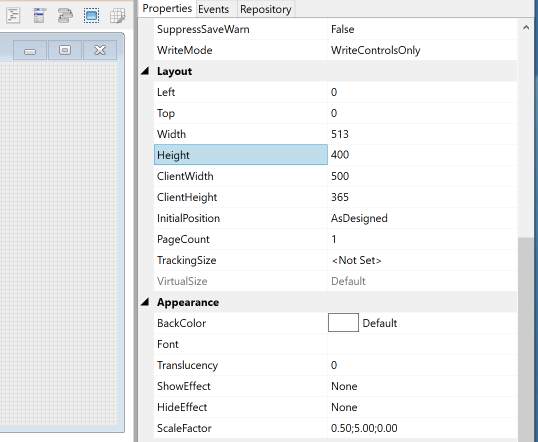
However, a little more testing against a form without a menu revealed another issue – in some cases a pixel was added to the Height but it didn’t creep up on each subsequent opening:
E.g. when set to a Height of 400 and saved, the form would re-open with a Height of 401, but it would stay at the same value afterwards; not the same bug as before but it did need investigating…
The Height and the ClientHeight properties
As some of you will know, Windows forms are split into two areas (1):
The “Nonclient area” which contains items such as the borders, menus and title bars, and
The “Client area”, which is the part that contains the controls.
When an OpenInsight form definition is saved the actual Width and Height properties are not used. Instead, the ClientWidth and ClientHeight properties (i.e. the dimensions of the Client area) are saved because Windows can change the size of the Nonclient parts when a form is run on different systems with different visual styles, and this can make the form’s Client area the wrong size when created from a saved Width and Height (as we all found out many years ago when Windows XP was released). In our particular case above, when the form was saved and reopened, the ClientWidth and ClientHeight properties were correct, but the Height had gained a pixel.
E.g. When set to a Height of 400, the saved form ClientHeight was 365. When the same form was reopened the ClientHeight was still 365, but the Height was now reported as 401.
Height, ClientHeight and High DPI
I run my primary and secondary monitors at different DPI settings to ensure that scaling works correctly, and in this case, at 192 DPI (i.e. scaled to 200%), it transpired that the integer rounding used during scaling was the issue because:
Setting the Height to 400 resulted in a ClientHeight of 365.
Setting the Height to 401 also resulted in a ClientHeight of 365.
Setting the ClientHeight to 365 resulted in a Height of 401.
I.e. setting the ClientHeight to a specific value, and then retrieving the form’s actual height in real pixels, and then scaling it back to 96 DPI (all values in the Form designer are shown and stored at 96 DPI), gave the extra pixel. Because we don’t record the Height in the form definition we have no way of knowing that the ClientHeight was set from a value of 400 rather than 401 when the form was reopened in the designer, so we have to go with the 401. Mystery solved!
Of course, this looks odd, but it’s just an artifact of the scaling calculations. The crucial value is the ClientHeight because this is the value that is recorded and used, and this is what needs to be preserved when forms are saved and reopened. To help put your mind at ease about this, the ClientWidth and ClientHeight properties have now been exposed (for forms only) in the Form Designer, so you can be confident that the correct size is always being maintained (ClientWidth and ClientHeight are normally runtime only properties).
E.g. In the following two images (saved and reopened) you can see that the pixel height has increased, but in both cases the ClientHeight (365) is preserved and is correct:
Form saved with a Height of 400
Form reopened, now with a Height of 401
Conclusion
Windows XP taught us many years ago that the Width and Height properties are not reliable when creating a forms as they can produce inconsistent results on different systems, so we always rely on the ClientWidth and ClientHeight properties instead.
Don’t be concerned if you see a slightly different Height value when you reopen a form if you’re running at a high DPI setting – the crucial property is the ClientHeight value – as long as this is consistent there is no actual problem.
To make sure you can monitor this yourself the ClientWidth and ClientHeight properties have been exposed in the Form Designer, and you can edit these directly if you wish.
(Note: the ClientHeight and ClientWidth properties are only exposed after builds later than the current Beta 3 release)
(1) If you are not familiar with Client and Nonclient areas in Windows GUI programming you can find out more information here).
We recently noticed a new bug in the IDE where a dialog that hadn’t been updated for quite some time suddenly started misbehaving: it would appear at the wrong coordinates (0,0), and then jump to the proper ones.
At first glance this this looked like a classic case of creating the dialog in a visible state, and then moving it during the CREATE event, but checking the dialog properties in the Form Designer showed that the dialog’s Visible property was “Hidden”, so this wasn’t the source of the problem.
Stepping through the CREATE event in the debugger showed that the dialog was indeed created hidden, but then became visible during an RList() call that performed a SELECT statement, ergo RList() was allowing some queued event code to execute (probably from an internal call to the Yield() procedure) and that was changing the dialog’s VISIBLE property.
Checking the other events revealed that the SIZE event contained the following code:
Call Set_Property( @Window, "REDRAW", FALSE$ )
// Move some controls around
Call Set_Property( @Window, "REDRAW", TRUE$ )
The REDRAW property works by toggling an object’s WS_VISIBLE style bit – when set to FALSE$ the style bit is removed but the object is not redrawn. When set to TRUE$ the object is marked as visible and redrawn.
So, putting all this together: creating the dialog generated a queued SIZE event, which under normal circumstances would run after the CREATE event. However, the Yield() call in RList() executed the SIZE event before the dialog was ready to be shown, and the REDRAW operation made the dialog visible before the CREATE event had moved it to the correct position.
The fix for this was to ensure that the REDRAW property wasn’t set to TRUE$ if it’s original value wasn’t TRUE$, like so:
bRedraw = Set_Property( @Window, "REDRAW", FALSE$ )
// Move some controls around
If bRedraw Then
Call Set_Property( @Window, "REDRAW", TRUE$ )
End
Conclusion
Always protect calls to the REDRAW property by checking its state before you set it, and then only turn it back on again if it was set to TRUE$ originally.
Calling Yield() can cause events to run out of the normal sequence, and you should be aware of this when writing your application.